

Atualizado em 23 de agosto de 2024
No últimos anos, aconteceu uma avalanche de dados em tempo real. Isso criou muitas oportunidades para empresas de todos os setores usarem a análise para entender e melhorar processos. Mas, para lidar com uma quantidade crescente de informações, é preciso encontrar formas de organização simples e automáticas. É aí que entra a orquestração de dados.
Em resumo, a orquestração é o processo coordenado de gerenciamento e direcionamento do fluxo de dados de uma organização. Isso permite que as empresas manipulem grandes volumes de dados de forma eficiente, garantindo que as informações corretas estejam no lugar certo, no momento certo.
Neste artigo, entenda o conceito e veja a aplicação na prática, em um case de orquestração de dados com Google Cloud e Apache Airflow. Além disso, conheça as ferramentas disponíveis e quais critérios você pode usar para definir a melhor opção para o seu projeto.

O que é orquestração de dados
A orquestração de dados é um processo automatizado que controla uma rede de tarefas, criando relações lógicas de dependência entre elas. Além disso, a orquestração permite o monitoramento dessa rede, ou do chamado pipeline. Mas o que isso quer dizer na prática?
Imagine que você é um engenheiro de dados trabalhando em um projeto que deve gerar relatórios para líderes de negócio da sua empresa. Sua equipe desenvolveu um código em Python para processar os dados, ou seja, fazer uma limpeza, definir o que é relevante e formatar tudo de acordo com um padrão. Esse código é executado periodicamente para assimilar informações novas. Porém, sempre que essa etapa é concluída, você também quer produzir um relatório no Microsoft Excel.
Você pode, é claro, observar o andamento do processo 24 horas por dia e ativar manualmente o novo relatório. Outra opção seria configurar uma ferramenta de agendamento de tarefas, com horário fixo para a execução das duas etapas. Porém, a solução mais eficiente seria estabelecer uma relação de dependência entre elas, usando uma ferramenta própria para orquestração de dados. Dessa forma, nenhum trabalho manual seria necessário, nem de estipulação de horário.
Assim, a orquestração permite que o engenheiro de dados mantenha o controle sobre o fluxo do pipeline de dados e garanta o máximo de eficiência.
Qual é o objetivo?
O objetivo principal da orquestração de dados é garantir que os processos de tratamento de dados aconteçam de forma automatizada, sem necessidade de intervenção manual. A orquestração cria um fluxo de trabalho estruturado, em que cada tarefa é executada em uma ordem específica, dependendo da conclusão bem-sucedida das etapas anteriores.
Dessa forma, cada etapa do processo acontece no momento em que deve acontecer. Isso não só reduz a chance de erros humanos, como também otimiza o uso dos recursos.
Além disso, uma ferramenta de orquestração de dados gera um panorama de todo o pipeline para o engenheiro de dados. Assim, ele pode identificar rapidamente qualquer falha ou gargalo no processo. Com isso, pode minimizar as interrupções em uma linha de produção, por exemplo. Além disso, ele garante que os dados estejam sempre prontos e disponíveis para as próximas etapas, como análises ou geração de relatórios.
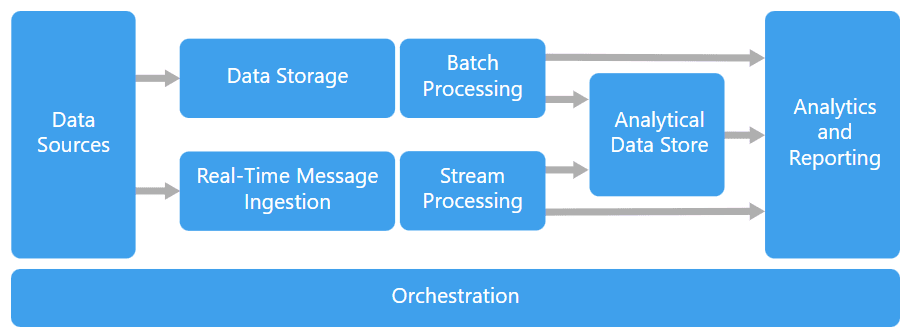
Isso sempre existiu?
Nem sempre foi preciso orquestrar dados. No início da internet, havia um padrão de arquitetura monolítica, em que um único software ficava responsável por todas as camadas de uma aplicação. Ou seja, nele aconteciam desde os processos internos de governança de dados até os externos, como interação direta com o usuário. Esse padrão implicava uma série de problemas. Os códigos se tornavam muito grandes e complexos, difíceis de manter e ajustar quando necessário. A falha de uma camada, por exemplo, poderia causar a falha de várias outras.
Mas, com o tempo, surgiram recursos tecnológicos com finalidades mais específicas, como serviços só para processamento ou disponibilização de dados. Também surgiu a nuvem, um modelo de computação flexível, que pode ser acessado em diferentes redes de internet. Diante de tantas mudanças, desenvolveu-se uma nova abordagem: a chamada arquitetura de microsserviços.
Nela, uma aplicação tem diversas camadas independentes uma da outra e existe um software diferente para realizar cada tarefa, possivelmente em máquinas diferentes. Essa arquitetura, apesar de vantajosa, também gera novos desafios. É preciso movimentar os dados e fazer o processamento de forma eficiente. O maior desafio é criar a dependência entre as tarefas. Para solucionar esse problema, precisamos de orquestração de dados!
Benefícios da orquestração de dados
A orquestração oferece diversos benefícios para a gestão de processos com dados. Ela não só organiza as tarefas, como também garante a qualidade das informações. Veja os principais benefícios que a orquestração de dados pode gerar para o seu projeto.
- Segurança: Com a automatização dos processos e sem a necessidade de intervenção manual, os erros humanos são eliminados. Além disso, é possível monitorar cada etapa do pipeline em tempo real. Isso facilita a identificação e a correção de problemas rapidamente.
- Escalabilidade: Ferramentas de orquestração de dados podem ser integradas com vários serviços. Assim, fica fácil assimilar novas fontes de dados, por exemplo. Você pode se adaptar às mudanças nas demandas do negócio e escalar as operações conforme necessário.
- Flexibilidade: As dependências entre as tarefas são claras e ficam centralizadas no mesmo ambiente. Isso facilita o ajuste de qualquer parte do pipeline sem comprometer o restante do fluxo de trabalho.
- Redução de custos: Ao automatizar processos que antes exigiam muita intervenção manual e supervisão, a orquestração de dados ajuda a reduzir os custos operacionais. Equipes de Tecnologia podem focar em tarefas de maior valor agregado, enquanto a infraestrutura de orquestração cuida das operações repetitivas.
- Complexidade: Com ferramentas integradas com bancos de dados, serviços de armazenamento na nuvem e ferramentas de análise, é possível orquestrar fluxos complexos. Eles podem interagir com diversas tecnologias, o que aumenta a interoperabilidade e o alcance das operações de dados.
Conheça as ferramentas de orquestração de dados
Existem diversas ferramentas específicas para orquestração de dados que fornecem soluções completas. Elas permitem monitorar o andamento das atividades e estabelecer relações complexas entre as partes, com diferentes gatilhos (ou triggers, em inglês). Porém, elas podem ter propósitos finais diferentes. Conheça algumas das ferramentas mais usadas:
Apache Airflow
Apache Airflow reúne todos os elementos em Python, a linguagem de programação predominante na área de Engenharia de Dados. Além disso, é um ambiente de código aberto (ou open source), onde existe uma comunidade ativa de desenvolvedores. É o nome mais conhecido quando se fala em orquestração de dados.
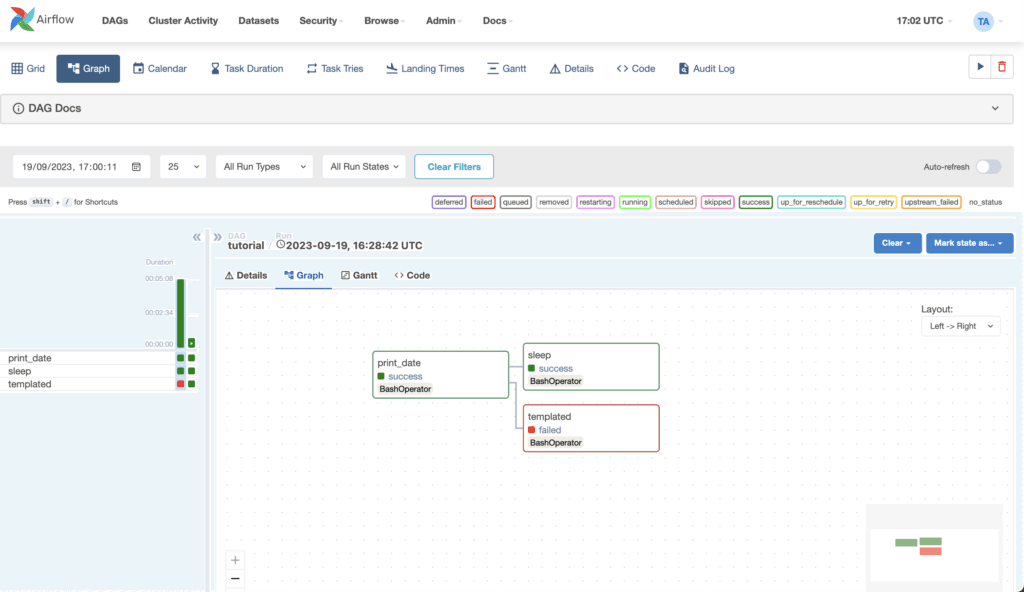
O Airflow se baseia no conceito de DAGs, uma sigla para Directed Acyclic Graph (Grafo Acíclico Dirigido). As DAGs agrupam tarefas e as relações entre elas, definindo como deve ser a execução do processo. Ele permite criar lógicas complexas, em que a execução depende de todos ou pelo menos um dos passos anteriores ter sido completado, ou nenhum.
Foi criado em 2014 para lidar com o fluxo de informações do aplicativo Airbnb. Só em 2016, se tornou um projeto open source da Apache.
Dagster
Dagster é uma ferramenta relativamente nova que se propõe a melhorar a experiência do desenvolvedor, especialmente em termos de testabilidade, modularidade e escalabilidade.
Ao contrário do Airflow, que foca na execução de tarefas, o Dagster se volta para o pipeline como um todo. Os usuários podem especificar não só como as tarefas são executadas, mas também como os dados fluem entre essas tarefas. Assim, é possível definir, testar e executar fluxos de forma mais intuitiva.
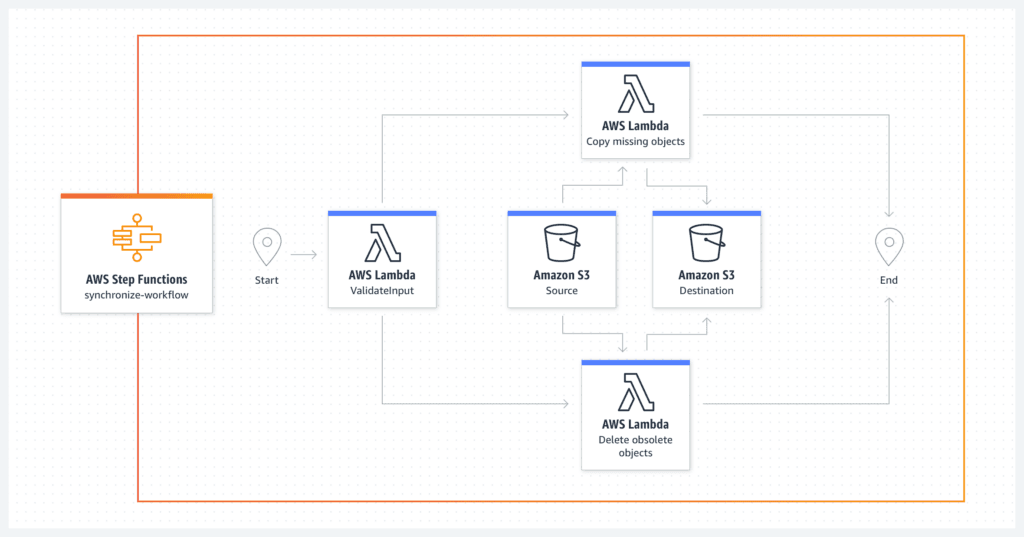
AWS Step Functions
AWS Step Functions é uma ferramenta da Amazon Web Services (AWS), que se integra perfeitamente com outros serviços da AWS, como Lambda e S3. Por isso, o Step Functions é especialmente útil para empresas que já operam na infraestrutura da AWS.
Além disso, uma das suas maiores vantagens é a simplicidade. O Step Functions não exige conhecimento profundo de programação e a sua natureza serverless também elimina a necessidade de gerenciar servidores. Assim, ele permite a criação de fluxos de trabalho escaláveis com pouca configuração adicional.
Data Factory
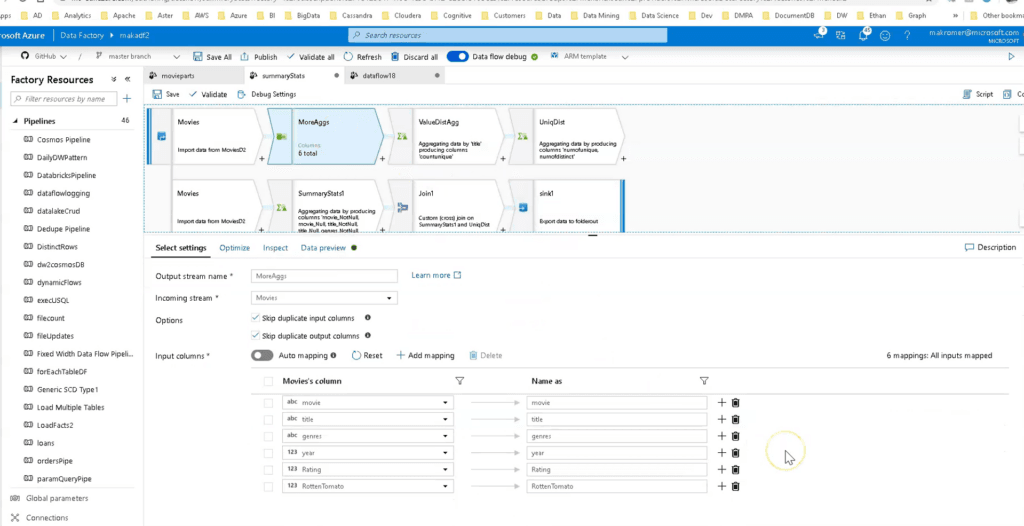
Data Factory é a ferramenta de orquestração de dados da Microsoft e faz parte da sua plataforma de nuvem Azure. É especialmente poderoso porque permite realizar atividades de ETL diretamente dentro do pipeline.
Entre as suas características, destacam-se a interface com botões de arrastar e soltar e a possibilidade de integrar scripts customizados.
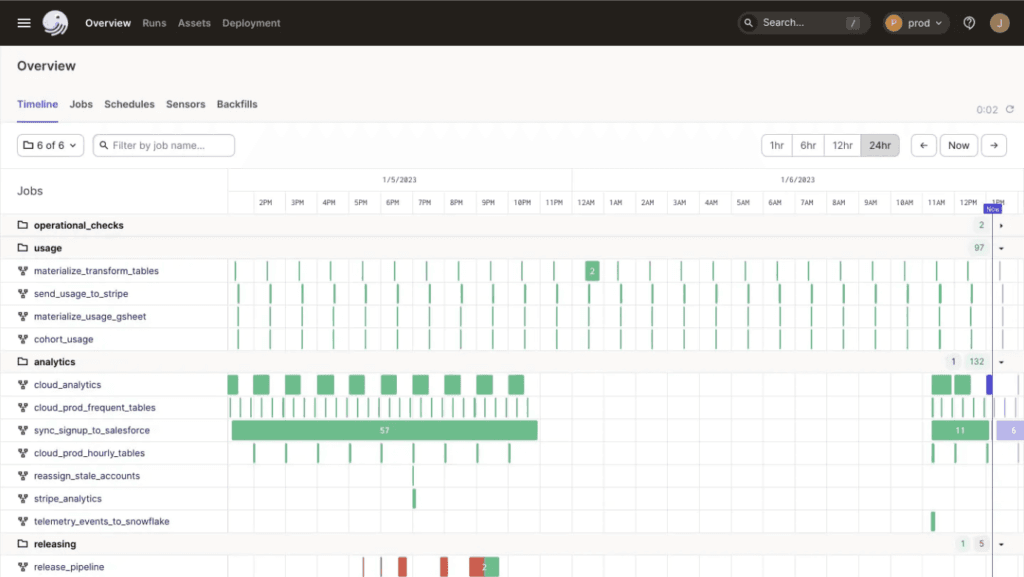
Flyte
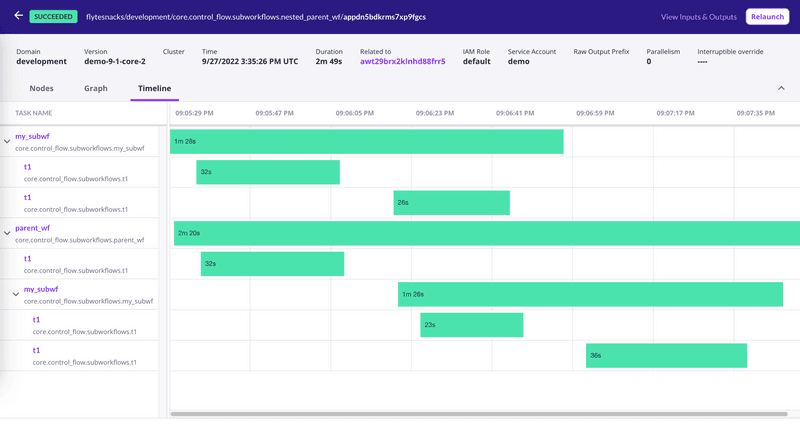
Flyte é uma plataforma open source que se destaca pelo foco em Machine Learning e pipelines complexos de Ciência de Dados. Uma das suas principais características é a capacidade de gerenciar a execução de tarefas de forma granular. Ele permite a reutilização de componentes e a execução de tarefas em paralelo ou em sequência, conforme necessário.
Além disso, o Flyte tem integração nativa com ecossistemas como Kubernetes e Spark. Isso possibilita que modelos de aprendizado de máquina sejam treinados, validados e implantados de forma eficiente.
A arquitetura modular e extensível também torna o Flyte uma escolha relevante para empresas que precisam de mais flexibilidade.
Como escolher a melhor ferramenta para o seu projeto
A escolha de uma ferramenta de orquestração de dados é uma decisão estratégica que pode impactar diretamente no seu projeto. Com várias opções disponíveis no mercado, é importante considerar uma série de fatores que vão além das funcionalidades técnicas.
Veja os principais fatores que você deve considerar para tomar uma decisão informada.
Alocação de recursos
É importante considerar os custos diretos e indiretos de cada opção. Ferramentas open source, embora ofereçam licenças gratuitas, podem implicar custos significativos com treinamento, suporte e tempo de trabalho para garantir que a solução opere da forma adequada.
Já ferramentas pagas, apesar de exigirem um investimento inicial mais alto, geralmente incluem suporte técnico e atualizações regulares. A longo prazo, essa escolha pode economizar tempo e recursos.
Tamanho da equipe
Uma ferramenta que exige manutenção contínua pode sobrecarregar os membros de uma equipe pequena. Nesse caso, ferramentas mais fáceis de manter permitem que a equipe concentre seus esforços em atividades estratégicas.
Além disso, é importante considerar a preparação técnica da equipe para utilizar a ferramenta. Se não existir um time de dados consolidado ou se o líder dessa iniciativa não tiver formação técnica, espere uma curva de aprendizado mais longa e demorada.
Mesmo em equipes com engenheiros de dados experientes, esses profissionais podem priorizar outras demandas. Por isso, ferramentas low-code, com pouco uso de código, podem ser mais vantajosas. Essas ferramentas permitem que usuários com menos conhecimento técnico configurem e mantenham pipelines de dados, aliviando a carga sobre os especialistas.
Escopo das atividades
Por último, mas igualmente relevante, é necessário considerar o tipo de tarefas que serão realizadas no seu pipeline. Por exemplo, talvez você precise ingerir dados de uma ferramenta de e-commerce específica. Algumas ferramentas de mercado já podem oferecer conectores prontos para facilitar a implementação da sua pipeline nesse cenário.
Por outro lado, pode ser necessário um driver ou plugin específico para conectar uma máquina específica que faz parte da sua stack e, para isso, será preciso uma ferramenta um pouco mais personalizada. Quanto à customização, uma ferramenta não gerenciada, onde a infraestrutura está sob sua responsabilidade, ganha destaque, pois permite o gerenciamento de demandas mais específicas que um serviço gerenciado por vezes não consegue atender.
Isso inclui a conectividade com outros serviços. As ferramentas low-code se propõem a realizar essas integrações de forma mais rápida e fácil, dispondo de conectores para facilitar o processo.
Compatibilidade com a infraestrutura atual
A integração da nova ferramenta de orquestração de dados com as infraestruturas já existentes na empresa é um dos pontos mais importantes a considerar. Uma boa ferramenta de orquestração deve se conectar facilmente com bancos de dados, serviços de nuvem, ferramentas de análise e outras plataformas que compõem o seu ecossistema de dados. Ferramentas como o Apache Airflow e o AWS Step Functions, por exemplo, oferecem integrações nativas que podem simplificar esse processo.
Além disso, é importante avaliar se a ferramenta pode se adaptar a novas tecnologias e serviços que possam ser adotados no futuro. À medida que sua infraestrutura evolui, a ferramenta de orquestração deve ser capaz de acompanhar sem a necessidade de uma reconfiguração completa. Nesse sentido, erramentas com ecossistemas ativos e suporte contínuo tendem a ser mais adaptáveis.
Precisa de orquestração de dados na sua organização? Deixe que a BIX faça isso para você!
Se você está enfrentando desafios na orquestração de dados em sua organização, a BIX Tecnologia está aqui para simplificar esse processo para você! Nossa expertise nos capacita a oferecer soluções personalizadas para as necessidades específicas da sua empresa.
Clique no banner abaixo e entre em contato conosco para descobrir como podemos impulsionar a eficiência e a inteligência dos seus dados. Estamos prontos para transformar seus desafios em oportunidades de crescimento!







