

Atualizado em 1º de outubro de 2024
Se você está começando na área de dados, pode se sentir frustrado ao se deparar com outliers, números que parecem fora do lugar. Essas discrepâncias deixam sua análise confusa e difícil de interpretar. A boa notícia é que você não está sozinho! Isso faz parte do caminho de qualquer profissional de dados. O importante é saber como lidar com esses desafios sem comprometer a qualidade do seu trabalho.
Neste artigo, você vai aprender a identificar e tratar anomalias nos dados, garantindo que suas análises continuem precisas e confiáveis. Continue lendo e descubra como superar esses obstáculos com mais confiança e tranquilidade.

O que são outliers?
No livro Fora de Série, o jornalista Malcom Gladwell faz uma definição clara de “outlier” e “fora de série”:
- Outlier: Algo que está afastado ou é classificado de forma diferente do corpo principal. Na estatística, é uma observação cujo valor é marcadamente diferente dos demais.
- Fora de Série: Algo que foge do comum, excepcional ou singular.
Esses conceitos capturam bem a essência do que é um outlier: uma anomalia nos dados, algo que se desvia do padrão estabelecido na amostragem. Em outras palavras, é um valor que não segue o comportamento esperado.
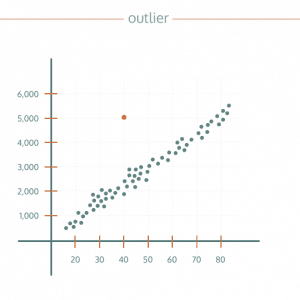
Por exemplo, imagine que você está analisando os salários de uma equipe em uma empresa, e todos os funcionários ganham entre R$ 5.000 e R$ 10.000, exceto por um gerente que recebe R$ 50.000. Esse salário muito acima da média é um claro exemplo de outlier. Outro exemplo comum está em tempos de atendimento ao cliente: se a maioria dos atendimentos leva de 5 a 10 minutos, mas um deles levou 90 minutos, esse número fora do padrão é um outlier que precisa ser investigado.
Encontrar outliers é comum ao lidar com grandes volumes de dados, por isso é fundamental aprender a lidar com eles. Eles podem revelar insights importantes, assim como podem distorcer os resultados da sua análise.
Por que os outliers são um problema?
Outliers podem se tornar um grande obstáculo em análises de dados. A razão é simples: esses valores extremos têm o potencial de distorcer as médias, desviar os padrões e, em alguns casos, mascarar tendências verdadeiras. Quando um outlier passa despercebido ou não é tratado adequadamente, ele pode fazer com que os resultados da sua análise fiquem imprecisos ou até mesmo incorretos.
Por exemplo, se você estiver analisando o tempo médio de atendimento de uma central de suporte e houver um caso atípico em que o atendimento durou muito mais tempo do que o normal, esse valor pode elevar a média geral de forma significativa, dando a falsa impressão de que a eficiência da equipe está abaixo do esperado.
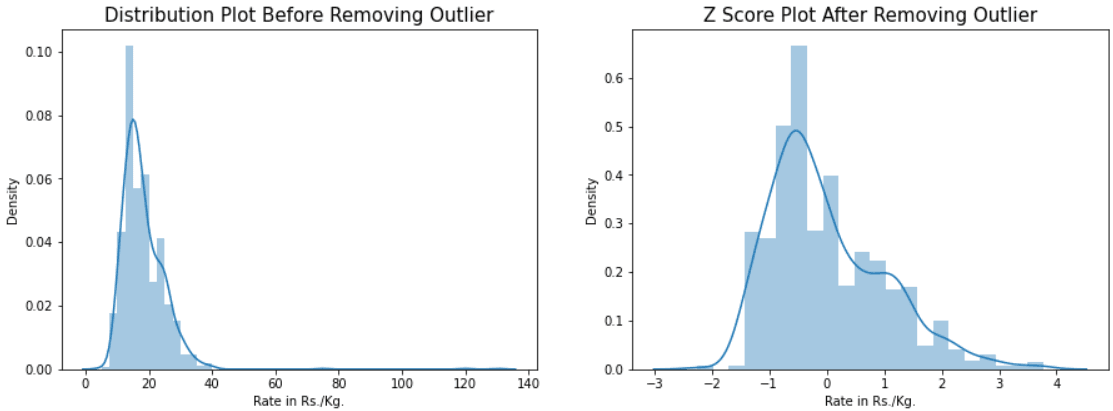
Além disso, os outliers podem levar à tomada de decisões equivocadas, especialmente quando influenciam métricas críticas, como lucro, performance ou satisfação do cliente. Identificar e tratar esses valores de forma correta é essencial para garantir que suas decisões se baseiem em dados confiáveis e representativos.
Como posso identificar um outlier?
Quando você está lidando com um conjunto de dados pequeno, identificar um outlier pode ser uma tarefa simples. Em muitos casos, basta observar a tabela ou planilha, e qualquer valor que se destaque significativamente dos demais será fácil de notar. Essa análise visual funciona bem em datasets menores, onde as discrepâncias ficam evidentes à primeira vista.
Porém, à medida que o volume de dados aumenta, essa abordagem se torna menos prática. Planilhas com milhares de linhas dificultam a visualização de anomalias, e os outliers podem passar despercebidos. Por isso, para conjuntos de dados maiores, o uso de planilhas pode não ser suficiente para detectar inconsistências com eficiência.
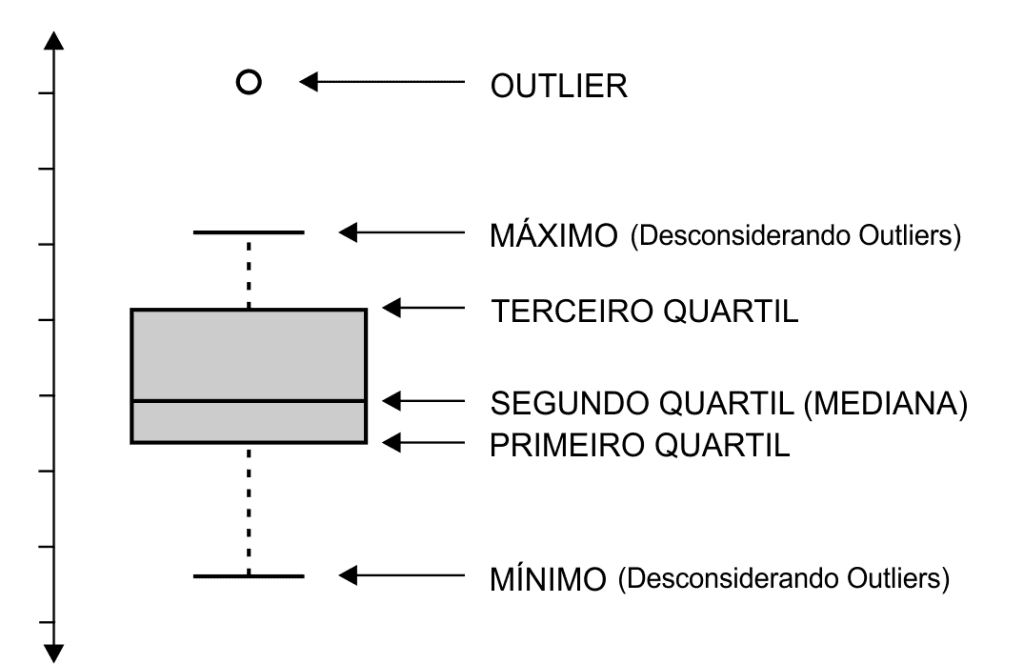
Nesses casos, uma das melhores estratégias é a plotagem de gráficos. Gráficos como boxplots, histogramas ou gráficos de dispersão são ótimas ferramentas visuais que ajudam a destacar valores que se desviam dos padrões esperados. Através dessas visualizações, o analista consegue identificar rapidamente qualquer anomalia que poderia comprometer a precisão da análise.
Qual é a causa dos outliers?
Antes de decidir a melhor forma de tratar um outlier, é fundamental entender a sua origem. Para isso, conheça os dois principais tipos de outliers: os naturais e os artificiais.
Outliers naturais
Outliers naturais ocorrem devido a variações normais nos dados e representam situações legítimas e esperadas, embora atípicas. Alguns exemplos disso são:
- Uma pessoa com idade avançada ao analisar a expectativa de vida em uma determinada região;
- Um indivíduo com renda significativamente superior ou inferior ao seu grupo econômico;
- Uma loja de varejo que vendeu muito mais do que as outras unidades da mesma rede;
- Um vendedor que ficou muito abaixo das metas estabelecidas para o mês.
Esses outliers fazem parte da realidade e muitas vezes revelam insights importantes sobre exceções em um grupo de dados. Um conselho ao lidar com outliers naturais é não descartá-los imediatamente; em vez disso, investigue-os para entender o que eles podem revelar sobre o fenômeno analisado. Muitas vezes, esses valores atípicos podem indicar tendências ou padrões relevantes.
Outliers artificiais
Por outro lado, a maioria dos outliers surge de erros artificiais, que ocorrem durante o processo de coleta, processamento ou manipulação dos dados. Esses erros podem ser classificados em cinco categorias principais:
- Erro de input (entrada de dados): erros de digitação ou coleta incorreta de informações. Por exemplo, ao registrar uma venda de R$ 500, pode-se digitar acidentalmente R$ 50.000, criando um outlier que não reflete a realidade.
- Erro de amostragem: ocorre quando dados de diferentes grupos estão misturados, como ao avaliar o desempenho de uma única unidade de uma rede de lojas, mas incluir acidentalmente dados de outras lojas. Isso pode gerar números inconsistentes e outliers artificiais.
- Erro de medida: acontece quando instrumentos de medição estão defeituosos ou mal calibrados. Um exemplo disso seria um termômetro que registra uma temperatura de 100°C em um ambiente onde o máximo deveria ser 30°C, criando um outlier que não corresponde à realidade.
- Erro ao processar dados: refere-se a erros durante o pré-processamento, como a aplicação incorreta de fórmulas. Por exemplo, se você confundir as unidades ao converter uma medida, pode gerar resultados que não fazem sentido.
- Erro intencional: esse tipo de erro ocorre quando os dados são manipulados deliberadamente, como em uma análise de crédito onde um solicitante inflaciona sua renda para ser aprovado, resultando em um outlier que não reflete seu verdadeiro perfil econômico.
Se o seu conjunto de dados está constantemente apresentando uma grande quantidade de outliers, é essencial revisar os processos de coleta e análise para garantir que a equipe não esteja cometendo algum desses erros.
Ok, já identifiquei meus outliers. E agora?
Se você acredita que um único outlier não representa uma ameaça significativa, é hora de repensar essa ideia. Um erro inicial sem correção pode se propagar e comprometer toda a análise de dados, funcionando como um efeito borboleta. Portanto, após identificar os dados discrepantes, você precisa adotar medidas para garantir que a eficácia da sua análise não vai ser prejudicada. Aqui estão algumas dicas sobre como proceder:
#1: Eliminar o valor
Se o seu dataset for suficientemente amplo, uma abordagem prática é excluir o valor anômalo. Essa remoção pode não causar grandes prejuízos à análise, principalmente se o outlier não representar uma parte significativa do conjunto de dados.
#2: Tratar separadamente
Se a quantidade de outliers for relativamente grande, uma opção é realizar uma análise separada somente com esses dados. É possível separá-los em dois grupos e criar modelos específicos para analisá-los. Essa solução é útil para investigar casos extremos, como por exemplo casos de empresas que continuam vendendo bastante e lucrando mesmo em tempos de crise.
#3: Transformação logarítmica
A transformação logarítmica é uma técnica que pode ajudar a reduzir a variação causada por valores extremos. Essa transformação é especialmente útil quando os dados seguem uma distribuição exponencial, tornando a análise mais robusta.
#4: Métodos de clusterização
Utilize esses métodos para achar uma aproximação que corrige e dá um novo valor aos outliers. Por exemplo, se os outliers forem causados por erros de input, ao invés de eliminar e perder uma linha inteira de registros, uma solução é usar algoritmos de clusterização. Esses algoritmos encontram o comportamento das observações mais próximas ao outlier e fazem uma interferência de qual seria o melhor valor aproximado.
Pronto para lidar com outliers e melhorar suas análises?
Identificar e tratar outliers é só o começo de uma análise de dados eficaz. Para aprofundar seus conhecimentos e aprimorar suas estratégias, explore mais conteúdos sobre como transformar dados em insights valiosos.
No blog da BIX Tecnologia, você encontra muitos tutoriais que podem lhe ajudar a se desenvolver como profissional de dados. Continue aprendendo e transforme sua análise de dados em decisões mais assertivas!






