

Atualizado em 2 de agosto de 2024
Às vezes, é difícil interpretar as decisões de uma Inteligência Artificial (IA). Os SHAP values, ou valores SHAP, foram criados para ajudar a vencer esse desafio.
Mas ainda é muito comum encontrar informações sobre SHAP totalmente em inglês ou com foco na teoria. Para profissionais de tecnologia com a rotina corrida, como eu, a explicação precisa ser mais direta.
Por isso, vou demonstrar aplicações práticas dos valores SHAP, assim como analisar seus resultados.

O que é SHAP?
SHAP um método relativamente recente, com menos de 10 anos. Seu objetivo é explicar o compartamento de modelos de IA de forma mais intuitiva, fugindo de soluções do tipo “caixa preta”.
A sigla SHAP significa SHapley Additive exPlanations, ou seja, Explicações Aditivas de Shapley, em referência ao matemático Lloyd Shapley. O conceito se baseia na teoria dos jogos e, por trás dele, existe uma matemática robusta. Para se aprofundar no tema, recomendo a leitura deste artigo em inglês. Mas, para utilizar essa metodologia no dia-a-dia, não é preciso entender tudo.
O que são SHAP values?
SHAP values, ou valores SHAP, são valores que podem ser atribuídos a cada característica de um modelo preditivo para ajudar a interpretar seu comportamento. Características com valor SHAP positivo são aquelas que impactam positivamente na predição, enquanto valor SHAP negativo indica impacto negativo.
Essa metodologia é capaz de explicar, de forma gráfica, como modelos de Inteligência Artificial chegam em seus resultados. Ou seja, através da leitura de gráficos, podemos entender as tomadas de decisão em Machine Learning de forma simplificada. Assim, também fica mais fácil levar esse conhecimento para profissionais de outras áreas, como líderes e representantes comerciais.
SHAP values na prática
Para aplicar os conceitos de SHAP na prática, vamos interpretar dados da Pima Indians Diabetes Database com este modelo de predição binária baseado em árvores. Ou seja, vamos analisar a probabilidade de um diagnóstico de diabetes a partir de critérios como idade, pressão sanguínea e concentração de glicose.
Para a construção de toda a análise, vamos utilizar a biblioteca shap, mantida inicialmente pelo autor que originou o método e agora por uma grande comunidade de SHAP.

Cálculo de SHAP values
Primeiramente, vamos calcular os valores SHAP seguindo os tutoriais do pacote:
# Biblioteca
import shap
# Cálculo do SHAP - Definindo explainer com características desejadas
explainer = shap.TreeExplainer(model=model)
# Cálculo do SHAP
shap_values_train = explainer.shap_values(x_train, y_train)Aqui, estamos:
- Definindo um
explainercom os parâmetros desejados. Existe uma diversidade de parâmetros paraTreeExplainer! Recomendo checar as opções na biblioteca. - Calculando os valores SHAP para o conjuntos de
train.
Note que eu defini um TreeExplainer. Meu modelo é baseado em árvores, por isso, existe um explainer específico na biblioteca para esta família de modelos.
Com o conjunto de valores SHAP já definidos para o nosso conjunto de treinamento, podemos avaliar como o valor de cada variável influenciou no resultado alcançado pelo modelo preditivo. Neste caso, vamos avaliar os resultados dos modelos em termos de probabilidade, ou seja, a porcentagem X que o modelo apresentou para dizer se a classe correta é 0 (não tem diabetes) ou 1 (tem diabetes).
Vale ressaltar que isso pode variar de modelo para modelo: usando um modelo XGBoost, por exemplo, nosso resultado padrão provavelmente não seria em termos de probabilidade como o da random forest do pacote sklearn. Para corrigir isso, poderíamos mudar os parâmetros de TreeExplainer.
Interpretação de SHAP values
SHAP values em conjunto
E agora, como interpretar os valores de SHAP? Para responder essa pergunta, vamos calcular o resultado de probabilidade de predição do conjunto de treino para uma amostra qualquer que previu valor positivo:
# Probabilidade de predição do conjunto de treino
y_pred_train_proba = model.predict_proba(x_train)
# Vamos agora selecionar um resultado que previu como positivo
print('Probabilidade do modelo prever negativo -',100*y_pred_train_proba[3][0].round(2),'%.')
print('Probabilidade do modelo prever positivo -',100*y_pred_train_proba[3][1].round(2),'%.')
O código acima gerou a probabilidade do modelo prever as duas classes:
- Probabilidade do modelo prever negativo – 17.0 %.
- Probabilidade do modelo prever positivo – 83.0 %.
Vamos visualizar os valores de SHAP para essa amostra de acordo as classes possíveis:
# Valores de SHAP para essa amostra na classe positiva
shap_values_train[1][3]array([-0.01811709, 0.0807582 , 0.01562981, 0.10591462, 0.11167778, 0.09126282, 0.05179034, -0.10822825])
# Valores de SHAP para essa amostra na classe negativa
shap_values_train[0][3]array([ 0.01811709, -0.0807582 , -0.01562981, -0.10591462, -0.11167778,-0.09126282, -0.05179034, 0.10822825])
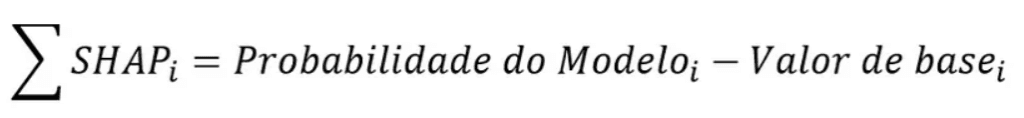
Vamos verificar isso em código:
# Somatório dos valores SHAP para classe positiva
print('Somatório SHAP para classe negativa nesta amostra:',100*y_pred_train_proba[3][0].round(2)-100*expected_value[0].round(2))
print('Somatório SHAP para classe positiva nesta amostra:',100*y_pred_train_proba[3][1].round(2)-100*expected_value[1].round(2))Somatório SHAP para classe negativa nesta amostra: -33.0
Somatório SHAP para classe positiva nesta amostra: 33.0Note que os valores SHAP correspondem com o resultado anterior.
E fica a reflexão: o valor do somatório de valores SHAP de uma classe x adicionado ao valor de base daquela classe resulta exatamente no valor de probabilidade do modelo encontrado no início dessa seção!
SHAP values individuais
Mas individualmente, o que os valores SHAP representam? Para descobrir isso, vamos usar mais código, usando como referência a classe positiva:
for col, vShap in zip(x_train.columns, shap_values_train[1][3]):
print('###################', col)
print('Valor SHAP associado:',100*vShap.round(2))################### Pregnancies
Valor SHAP associado: -2.0
################### Glucose
Valor SHAP associado: 8.0
################### BloodPressure
Valor SHAP associado: 2.0
################### SkinThickness
Valor SHAP associado: 11.0
################### Insulin
Valor SHAP associado: 11.0
################### BMI
Valor SHAP associado: 9.0
################### DiabetesPedigreeFunction
Valor SHAP associado: 5.0
################### Age
Valor SHAP associado: -11.0Aqui, avaliamos, para a amostra 3, os valores SHAP referentes à classe positiva. Valores SHAP positivos como de Glucose, BloodPressure, SkinThickness, BMI e DiabetesPedigreeFunction influenciaram o modelo na previsão da classe positiva como correta. Ou seja, valores positivos implicam uma tendência para a categoria de referência.
Já valores negativos como Age e Pregnancies buscam indicar que a classe verdadeira é a negativa (a oposta). Neste exemplo, se ambos fossem positivos, o nosso modelo resultaria em uma predição de 100% para a classe positiva. Como isso não aconteceu, eles representam os 17% que são contra a escolha da classe positiva.
Em resumo, podemos pensar em SHAP como contribuições para que o modelo decida entre uma das classes. Assim,
- O somatório dos valores SHAP não podem ultrapassar 50%.
- Valores positivos considerando uma classe de referência indicam ser favoráveis aquela classe na predição.
- Valores negativos indicam que a classe correta não é aquela de referência, mas sim outra classe.
Além disso, podemos quantificar em termos de porcentagem a contribuição de cada variável na resposta final daquele modelo dividindo pelo máximo de contribuição possível, neste caso, 50%:
for col, vShap in zip(x_train.columns, shap_values_train[1][3]):
print('###################', col)
print('Valor SHAP associado:',100*(100*vShap.round(2)/50).round(2),'%')################### Pregnancies
Valor SHAP associado: -4.0 %
################### Glucose
Valor SHAP associado: 16.0 %
################### BloodPressure
Valor SHAP associado: 4.0 %
################### SkinThickness
Valor SHAP associado: 22.0 %
################### Insulin
Valor SHAP associado: 22.0 %
################### BMI
Valor SHAP associado: 18.0 %
################### DiabetesPedigreeFunction
Valor SHAP associado: 10.0 %
################### Age
Valor SHAP associado: -22.0 %Aqui, conseguimos verificar que Insulin, SkinThickness e BMI tiveram juntas uma influência de 62%. Também podemos perceber que a variável Age consegue anular o impacto de SkinThickness ou Insulin nesta amostra.
Visualização de SHAP values
Um dos motivos do SHAP ter se tornado tão popular é a qualidade das suas visualizações, que, na minha opinião, superam as do algoritmo LIME.
Com visualizações em gráfico, podemos elaborar apresentações para discutir análises com colegas e líderes. Além disso, também podemos estruturar um case ou estudo de caso para mostrar habilidades a clientes e contratantes.
Na nossa análise, vamos usar esse recurso para fazer uma avaliação geral do conjunto de treino em relação a predição do nosso modelo para compreender o que está acontecendo no meio de tantas árvores.
Mas antes disso, precisamos entender as características dos gráficos:
- O eixo Y são as variáveis do nosso modelo em ordem de importância. O SHAP ordena isso de forma padrão, mas é possível escolher outra ordem através dos parâmetros.
- O eixo X são os valores SHAP. Como a nossa referência é a categoria positiva, valores positivos indicam um suporte para a categoria de referência, ou seja, contribuem para o modelo responder categoria positiva no final. Já valores negativos indicam um suporte à categoria oposta, que, neste caso de classificação binária, seria a classe negativa.
- Cada ponto no gráfico representa uma amostra. Cada variável tem 800 pontos distribuídos horizontalmente e, como são 800 amostras, cada amostra tem um valor para aquela variável. Note que essas nuvens de pontos em algum momento se expande verticalmente. Isso reflete a densidade de valores daquela variável em relação aos valores SHAP.
- Finalmente, as cores representam o aumento ou diminuição do valor da variável. Tons mais vermelhos são valores altos e tons azulados são valores mais baixos.
Contribução das variáveis
# Gráfico 1 - Contribução das variáveis
shap.summary_plot(shap_values_train[1], x_train, plot_type="dot", plot_size=(20,15));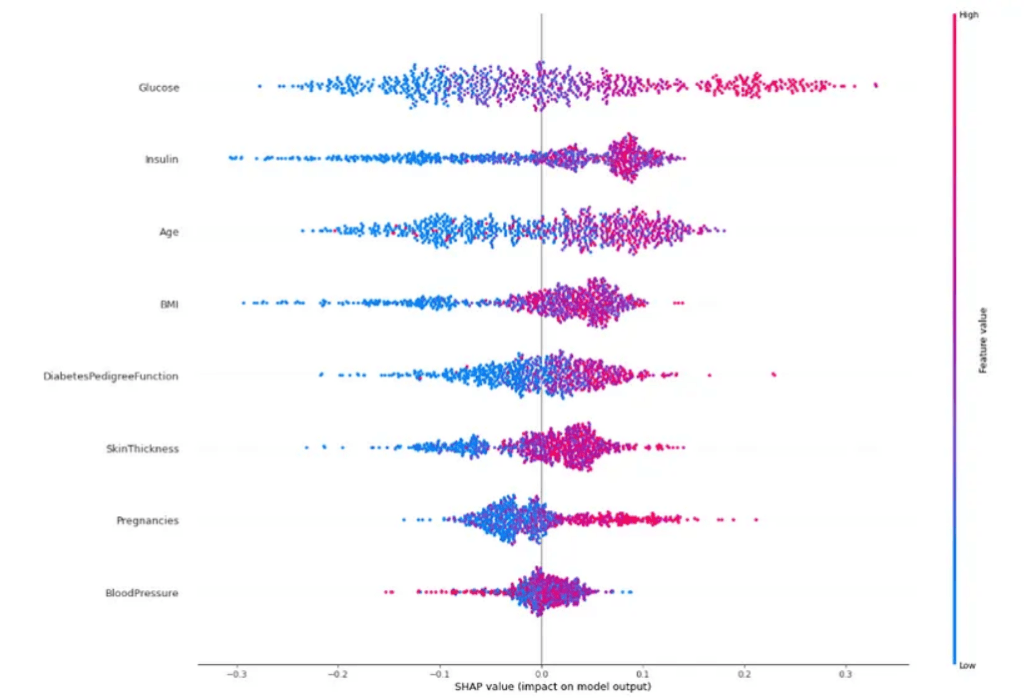
De forma geral, vamos buscar variáveis que:
- Tenham uma divisão bem clara de cores, ou seja, vermelho e azul em lugares opostos. Essa informação mostra que elas são bons previsores! Afinal, ao mudar apenas o valor dessas variáveis, o modelo consegue verificar de forma mais simples sua contribuição para uma classe.
- Além disso, quanto maior o intervalo de alcance de valores SHAP, melhor será aquela variável para o modelo.
Vamos considerar Glucose, que apresenta, em algumas situações, valores de SHAP em torno de 0,3, ou seja, 30% de contribuição para o resultado do modelo – isso porque o máximo que qualquer variável pode atingir é 50%. Tanto Glucose quanto Insulin possuem as duas características que estamos buscando.
Agora, observe a variável BloodPressure: seus valores SHAP ficam em torno de 0 (contribuições fracas) e com uma clara mistura de cores. Além disso, não vemos uma tendência de aumento ou diminuição dessa variável na resposta final.
Vale destacar também a variável Pregnancies, que não possui um intervalo tão grande como Glucose, porém demonstra uma divisão clara de cores.
Por meio desse gráfico, temos um panorama geral de como o modelo chega em conclusões a partir do conjunto de treinamento e das variáveis.
Contribução de importância das variáveis
Além de visualizações gerais, o SHAP proporciona análises mais individuais por amostras. Gráficos como esses são interessantes para apresentar algum resultado em especial. Por exemplo, se eu estivesse esteja trabalhando em um problema de churn de clientes e quisesse mostrar como meu modelo compreendeu a saída do maior cliente da empresa.
# Gráfico 2 - Contribução de Importância das variáveis
shap.summary_plot(shap_values_train[1], x_train, plot_type="bar", plot_size=(20,15));![Gráfico de barras de "mean([SHAP value]) (average impact on model output magnitude)".](https://images.bix-tech.com/shap_values_4_1024x623_1acb353cc3.png)
Esse gráfico é simples, por isso é mais recomendado em apresentações para profissionais com pouco conhecimento técnico, como lideranças comerciais.
Como o próprio título do eixo X demonstra, cada barra representa a média dos valores SHAP em módulo. Assim, avaliamos a contribuição média das variáveis nas respostas do modelo. Olhando para Glucose, vemos que sua contribuição média gira em torno de 12% para a categoria positiva.
Impacto das variáveis em uma predição Waterfall Plot
# Gráfico 3 - Impacto das variáveis em uma predição específica do modelo versão Waterfall Plot
shap.plots._waterfall.waterfall_legacy(expected_value=expected_value[1], shap_values=shap_values_train[1][3].reshape(-1), feature_names=x_train.columns, show=True)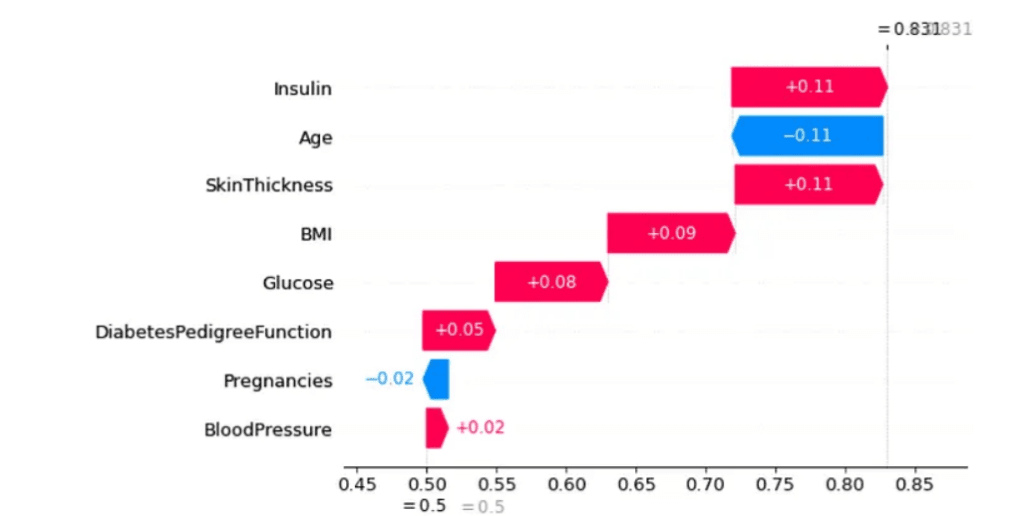
Neste gráfico, vemos que a predição começa na parte inferior e sobe até o resultado em probabilidade.
Cada variável contribui de forma positiva (modelo prever categoria positiva) e de forma negativa (modelo prever outra classe). Neste exemplo, vemos, por exemplo, que a contribuição de SkinThickness é anulada pela contribuição de Age.
Ainda neste gráfico, o eixo X representa os valores de SHAP e os valores das setas indicam as contribuições dessas variáveis.
Impacto das variáveis em uma predição Line Plot
# Gráfico 4 - Impacto das variáveis em uma predição específica do modelo versão Line Plot
shap.decision_plot(base_value=expected_value[1], shap_values=shap_values_train[1][3], features=x_train.iloc[3,:],highlight=0)
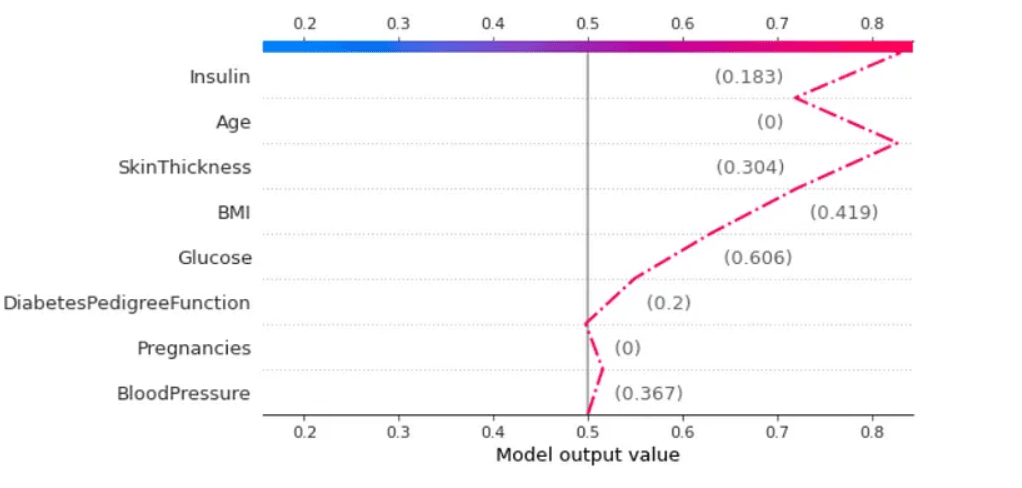
Neste gráfico, os valores próximos da seta indicam os valores das variáveis referente à amostra, e não aos valores SHAP.
Como nossa categoria de referência é positiva, o resultado do modelo se move em direção a tons mais avermelhados, na direita, o que indica uma predição para classe positiva. Para a esquerda, seria uma predição para a classe negativa.
Outras aplicações de SHAP

A partir dos SHAP values, compreendemos como os valores de cada variável influenciaram no resultado do modelo. Ao analisar as visualizações, o método SHAP nos permitiu interpretar resultados específicos e individuais, além de compreender o que o esquema expressa sobre o problema.
Apesar da matemática robusta, compreender essa metodologia é mais simples do que parece. E a tecnologia SHAP não para por aqui! Existem muitas coisas que podem ser feitas com essa técnica e, por isso, recomendo:
- Ler a documentação completa
- Avaliar outros métodos de interpretação de modelos em meu notebook
Ficou com dúvidas sobre o uso de SHAP no seu projeto? Compartilhe o seu desafio com a BIX! Vamos pensar juntos em uma estratégia de dados que faça sentido para você.
Escrito por Kaike Reis






