

Atualizado em 7 de agosto de 2024
O modelo ainda não aprendeu o suficiente ou já aprendeu demais? Se você não sabe como prosseguir com seu projeto de Machine Learning, você precisa entender o Bias-Variance Trade-off, ou Troca Viés-Variância. Esse conceito deve ser considerado na etapa de regularização do modelo e faz uma grande diferença na modelagem dos dados.
Ao ajustar corretamente a proporção entre as duas características, você garante a eficiência do seu programa e a qualidade das suas previsões.

O que é viés?
O viés (em inglês, bias) é uma tendência de comportamento. Em Machine Learning, significa que o modelo não considera todas as características da base de dados igualmente, ou seja, tende a favorecer algumas em detrimento de outras. Por isso, distorce a análise dos dados e o resultado final.
Em outras palavras, um modelo enviesado não representa a população em que opera com rigor e, assim, não reflete a realidade, o que leva a previsões imprecisas, erradas e um desempenho pior como um todo.
O que é variância?
A variância é uma medida de dispersão, conceito da área da Estatística, e indica quanto cada valor de uma base de dados se distancia do valor médio dessa base. Uma variância alta, por exemplo, sugere pontos bem distribuídos, com um amplo leque de valores. Já uma variância baixa sugere uma concentração maior de pontos em um mesmo intervalo.
Em Machine Learning, um modelo de alta variância é aquele que faz previsões muito diferentes do resultado esperado. Nesses casos, o algoritmo é altamente sensível a mudanças e, mesmo quando os valores de entrada são similares, as saídas são diferentes.
Viés e variância aplicadas a Machine Learning
O objetivo de um modelo preditivo de Machine Learning é prever uma resposta futura com base nos preditores passados (campos da sua base de dados que se relacionem com seu alvo resposta). Por exemplo, utilizar valores de oferta e demanda do último mês (preditores) para prever o preço de um produto no próximo mês (alvo).
Quando falamos em prever uma resposta, o primeiro passo é entender bem o passado dos seus dados. A ideia aqui é que, para saber se algo acontecerá, podemos simplesmente jogar uma moeda para o alto e “chutar” uma possibilidade ou podemos intuitivamente pensar que os acontecimentos futuros podem seguir determinados padrões que já ocorreram.
Por você estar lendo este artigo, a probabilidade é grande de você achar mais sensato utilizar a segunda opção: de aprender com os dados do passado, para prever o futuro. Então, caso eu fizesse uma pesquisa perguntando qual das duas opções você, leitor, acha mais sensata, eu teria respostas com alto viés a segunda opção. Esse viés ocorre pelo fato de eu utilizar “baixa variância” na coleta de meus dados. Caso eu fizesse a mesma pergunta em sites não relacionados à ciência de dados, minhas respostas poderiam ser diferentes, então se eu quiser respostas com menor viés eu devo aumentar minha variância, pronto, esse é o ponto que queremos chegar!
Níveis de viés e variância
Em uma linguagem simples, podemos dizer que um modelo de Machine Learning com alto viés “aprendeu pouco” e um modelo com muita variância “aprendeu demais”. Estas clássicas imagens demonstram com clareza este trade-off.
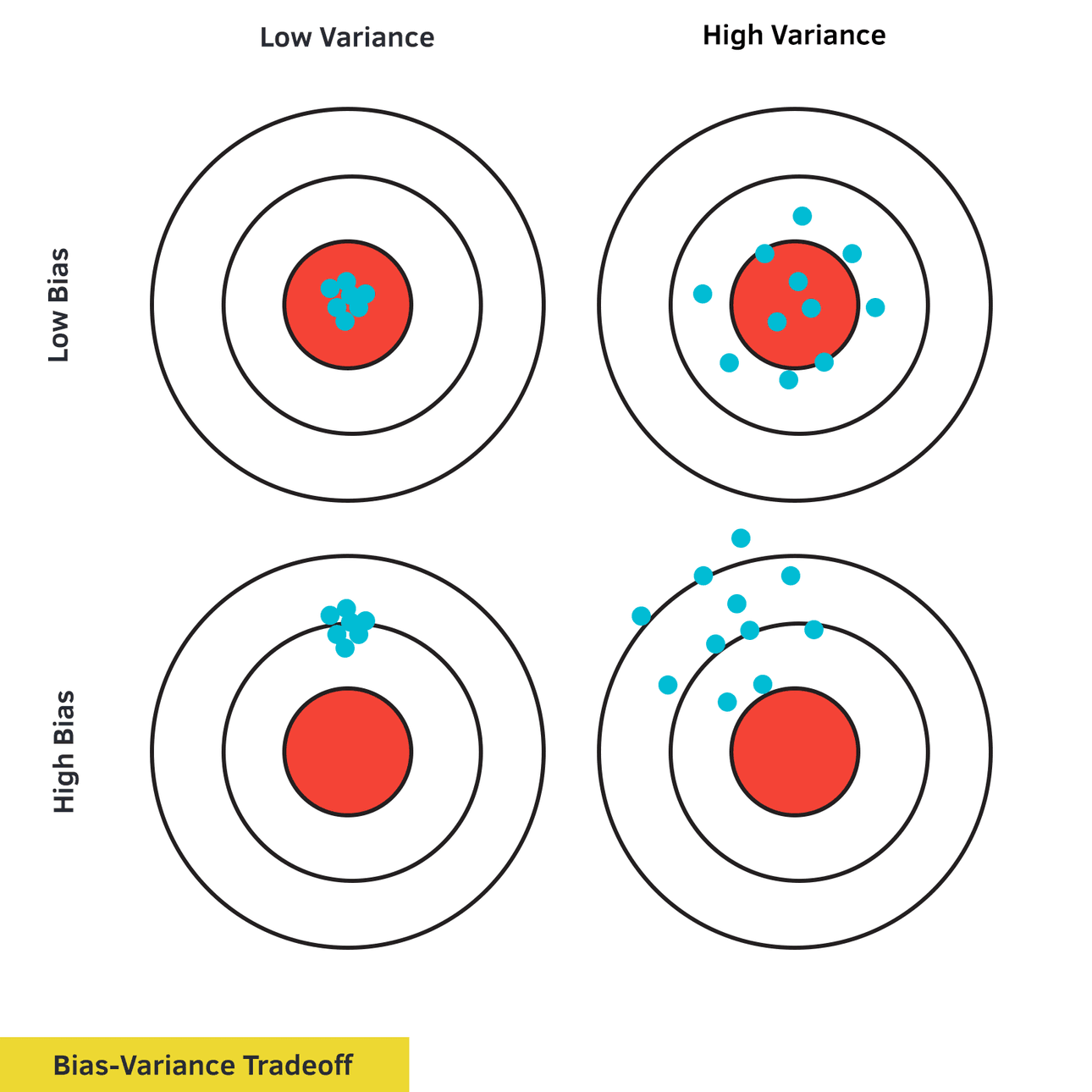
Seu objetivo é obter um resultado com baixo viés e baixa variância. Com isso, dedicaremos nossos esforços para chegar a um resultado mais próximo possível desta realidade para garantirmos boa acurácia e precisão nas nossas previsões.
O segundo alvo na parte superior (baixo viés e alta variância) exemplifica bem os casos de overfitting ou “os modelos que aprenderam demais.” Perceba que o excesso de ajuste com os dados de treino neste caso não permitiu uma boa generalização com os dados novos calhando em uma baixa precisão.
O primeiro alvo da parte inferior (alto viés e baixa variância) demonstra os casos de underfitting ou “os modelos que aprenderam pouco.” Neste caso, houve um sub treinamento ao ponto do modelo não ser capaz de capturar a real relação entre os dados calhando também em uma previsão falha.
O segundo alvo da parte inferior (alto viés e alta variância) demonstra os casos de total inconsistência preditora de nosso modelo.
Dependendo do modelo de Machine Learning que escolhemos utilizar ou do ajuste de seus parâmetros, conseguimos ajustar essa curva de aprendizado para a nossa base de dados, buscando construir um modelo que seja flexível o suficiente para se adaptar a variações dos dados de entrada e que represente bem sua tendência ou respeite sua distribuição.
Definições comuns: overfitting, optimum e overfitting
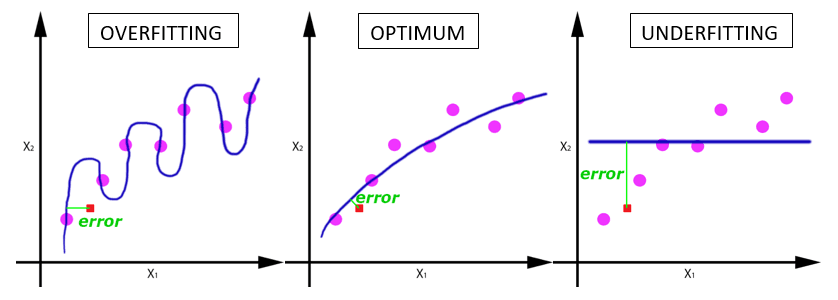
Vamos revisar os conceitos apresentados:
- Overfitting ou excesso de treinamento: modelo muito complexo, incapaz de generalizar resultados. O problema aqui é que este tipo de modelo é “viciado” nos dados em que ele foi treinado para aprender e qualquer variação de entrada de dados que fuja esse padrão será um problema.
- Underfitting ou pouco treinamento: modelo muito simples, que não se ajusta aos dados nem à sua distribuição. Esse tipo de ocorrência resulta em uma previsão falha e pouco assertiva.
Então, este é o famoso “cobertor curto”, no qual não podemos ter o melhor dos dois mundos e o papel do cientista de dados é encontrar o equilíbrio, se adequando ao seu modelo de dados e à realidade do seu problema.
Erros de viés e variância
Durante o processo de previsão, é possível que ocorram erros. Para evitar estas ocorrências e garantir um estudo otimizado, vamos ver como podem ser divididos os erros de previsão em um modelo de Machine Learning. Eles são:
- Erro irredutível
- Erro de variância
- Erro de viés
O erro irredutível ou “ruído”, o próprio nome nos diz: não pode ser reduzido. Ele independe do algoritmo utilizado e pode ser causado, por exemplo, por preditores mal enquadrados ou incompletos.
O erro de alto viés geralmente é cometido por algoritmos lineares, que apresentam facilidade no aprendizado, mas são pouco flexíveis. Com isso, estes modelos apresentam um desempenho inferior quando aplicados em problemas mais complexos, por exemplo, regressão linear e regressão logística. Alguns exemplos de algoritmos de baixo viés são KNN, SVM, árvores de decisão.
Você vai encontrar erros de alta variância em algoritmos não lineares, que apresentam grande flexibilidade mas pouca generalização. Exemplo de algoritmos de alta variação são árvores de decisão, KNN, SVM e de baixa variação podem ser regressão linear e logística.
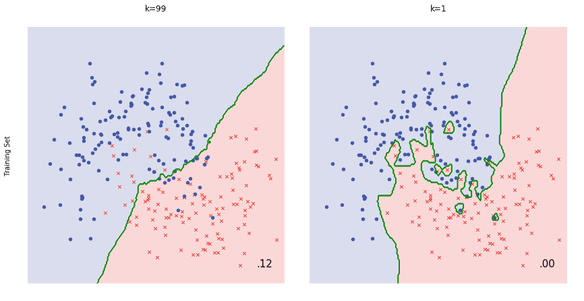
A ilustração acima mostra claramente um exemplo de baixo viés à esquerda e alto viés a direita. No algoritmo KNN, o ajuste é facilmente manipulado através da variável “K”, que serve justamente para fazer este balanço aumentando ou reduzindo a tendência do modelo.
Como evitar erros?
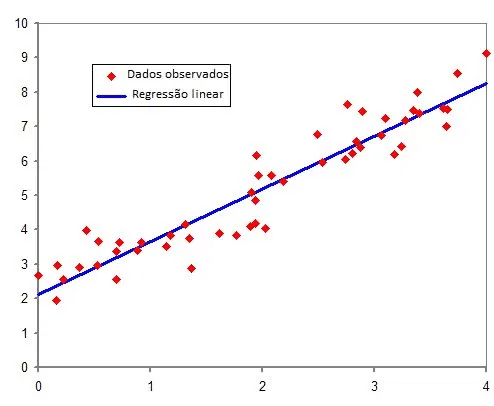
Se você está trabalhando com um modelo de regressão, pode aplicar a regularização. Você pode entender esse conceito como a inserção ou redução de viés em um algoritmo, podendo reduzir ou aumentar sua variância. Modelos como Lasso Regression, Ridge Regression e Elastic Net Regression são amplamente utilizados para acrescentar esse viés, de forma a torná-la mais generalista.
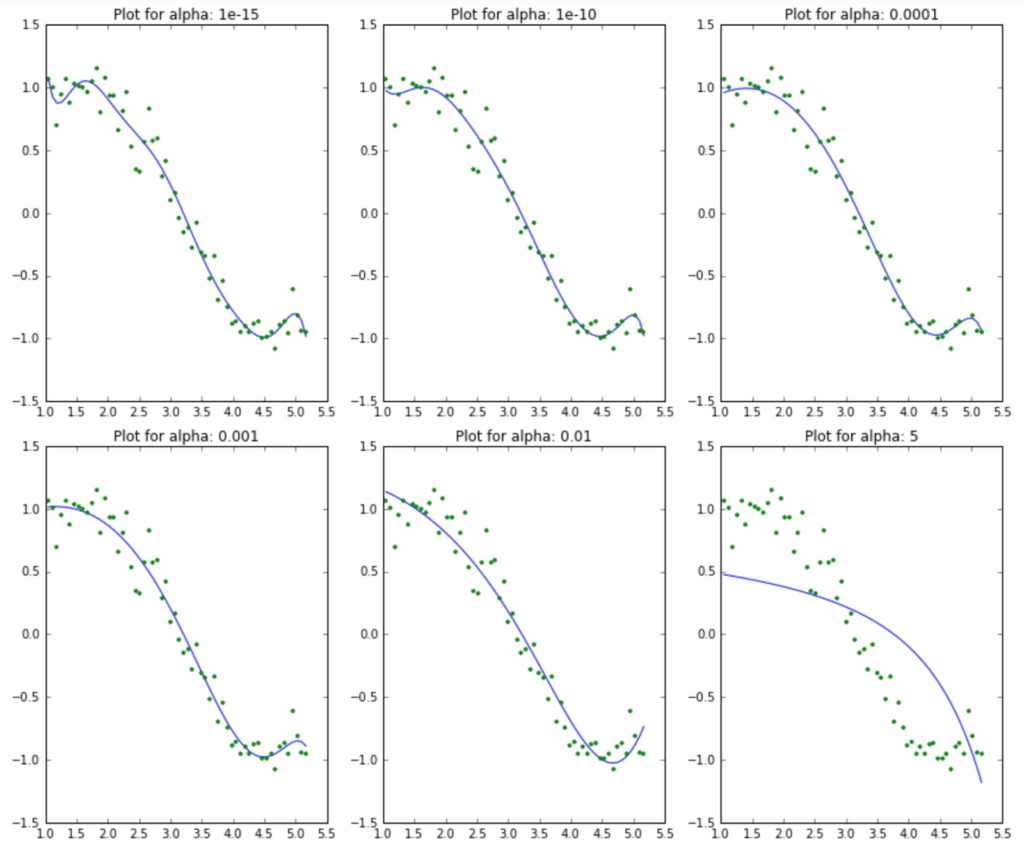
No exemplo de modelo de Ridge acima, é possível perceber visualmente o resultado do ajuste do parâmetro alpha na adequação do modelo (linha azul) a realidade dos dados (pontos verdes). A ideia aqui é ter a percepção visual desta mudança, mas na prática, o ideal é utilizar um parâmetro de comparação, como: (r², mae, mse) entre os diferentes alfas e identificar qual deles reduz mais o erro.
Outra técnica bastante interessante é a de cross validation, ou validação cruzada, que você pode usar para testar a capacidade de generalização de um modelo. A técnica faz divisões na base de dados de treino e teste e permite treinar e validar seus dados em diversos grupos distintos. Dessa forma, conseguimos mensurar a flexibilidade ou capacidade de generalização de um modelo antes mesmo da chegada de novos dados.

.
Dicas para dominar viés e variância
Agora que já entendemos um pouco sobre o trade-off viés e variância, seguem aqui algumas recomendações quando se for trabalhar com modelos preditivos de Machine Learning.
- Fazer uma boa análise exploratória de dados antes de escolher qual modelo utilizar. Esta etapa te ajudará a entender melhor sua base de dados além de direcionar qual tipo de modelo você poderá utilizar.
- Fazer a divisão da base de dados para treinar seus modelos com validação cruzada. Assim, você pode descobrir se o modelo é capaz de generalizar o suficiente mantendo uma performance satisfatória.
- Fazer ajustes inerentes no modelo, se possível, para balancear o viés e variância reduzindo assim o erro total.
- Por fim, mas não menos importante, avaliar se a quantidade de dados utilizada para a construção do modelo é suficiente. Uma pequena quantidade de dados de treino pode trazer problemas de generalização causando overfitting muito facilmente. Se este for o caso, tente conseguir mais dados para sua base.
Próximos passos
Para saber mais sobre aplicações, práticas e cases, entre em contato conosco! Vamos conversar sobre os âmbitos da Análise de Dados e ajudar sua empresa na conquista de resultados de impacto em todas as áreas do negócio.






