


Machine learning pode tornar a sua análise de risco mais eficiente – e mais fácil de fazer! A ideia não é superar o senso crítico de um analista humano, mas servir de instrumento para que ele mesmo supere sua performance. Isso pode mudar todo o negócio.
Analisar o risco de uma operação de crédito é necessário para quase todas as empresas, seja seu core business ou não. Por sorte, quanto mais repetitiva a tarefa, mais viável o uso de aprendizado de máquina, ou machine learning, para otimizar o processo.
A inteligência artificial pode ser mais assertiva e garantir mais segurança no seu trabalho, principalmente na sua tomada de decisão. Quer ver na prática? Nesse texto, vamos entender as capacidades técnicas dessa tecnologia e simular a implementação de um modelo de machine learning que economiza, ao fim, mais de R$ 12 milhões para a empresa.
Quem usa machine learning em análise de risco e para quê?
A análise de crédito é uma das principais atividades de um banco, mas há outros tipos de negócio que também precisam avaliar o risco de suas operações, como seguradoras e empresas de plano de saúde. Nesses dois casos, é necessário adequar a parcela cobrada do cliente ao seu potencial de risco, para que não haja perdas no pagamento de apólices, ou no momento do usufruto do plano de saúde.
Além disso, há lojas de varejo que oferecem cartão de crédito próprio para seus clientes. Ao prestar esse serviço, geralmente acompanhado de sistema de pontos e descontos exclusivos, é importante identificar o nível de responsabilidade financeira de cada um.
Por isso, em todos os cenários citados acima, é preciso que exista uma área de risco com profissionais qualificados para entender os diferentes perfis de clientes e operações e fazer as adequações necessárias.
Machine learning
Em um mundo em que:
- As informações disponíveis para análise aumentam exponencialmente;
- Os ambientes de negócios se tornam mais competitivos;
- Os clientes esperam (com razão) por um atendimento mais veloz, assertivo e de qualidade;
Uma única área de risco não seria capaz de acompanhar a evolução dos processos sem o auxílio de uma tecnologia avançada, que permita escalar suas análises. É aí que entra a Inteligência Artificial com capacidade de aprendizado de máquina, ou machine learning.
Essa tecnologia permite que um programa seja capaz de estudar as operações anteriores para prever, com cada vez mais exatidão, os resultados futuros. Isso é: o computador aprende, através de métodos estatísticos, quais circunstâncias levam a cada evento.
Análise de risco automatizada
Na análise de risco, então, é possível fornecer exemplos de operações perdidas ou fraudulentas para gerar um modelo matemático que prevê o grau de risco de uma operação nunca feita antes. Modelos como esse costumam ser adotados em dois contextos:
- Auxiliar na tomada de decisão dos profissionais que já realizam a análise de risco da empresa, classificando as operações mais arriscadas, além de informar quais variáveis podem explicar o porquê do risco ser maior ou menor;
- Automatizar a análise de risco, integrando-se completamente a outros sistemas e processos da empresa.
Como implementar machine learning em análise de risco?
Então, vamos criar um modelo de machine learning para análise de risco! Podemos trabalhar com uma base de dados do Kaggle, uma plataforma de aprendizado de machine learning, que contém informações de empréstimos de uma empresa indiana.
1) Conhecendo a base de dados
Estão disponíveis nessa base:
- 252 mil amostras para treinamento com respostas;
- 28 mil amostras para teste sem respostas;
- 13 variáveis de entrada como são apresentadas na tabela abaixo.
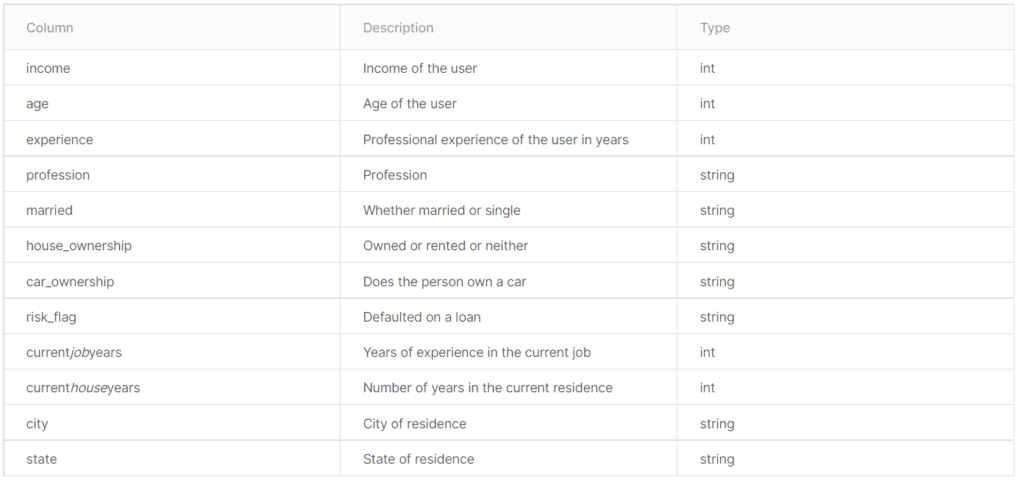
Ao carregar os dados, vamos cumprir as seguintes etapas:
- Entender a proporção entre as operações com e sem risco;
- Realizar uma checagem de realidade (do inglês sanity check) nos dados;
- Realizar uma limpeza básica de dados;
Nota: a partir deste ponto, serão omitidas etapas intermediárias no processo de tratamento dos dados para focar apenas no essencial. O notebook completo em Python pode ser consultado neste link.
Proporção entre operações de risco e sem risco
O gráfico abaixo demonstra a proporção entre as operações de risco (em que o cliente não honrou com os pagamentos) e as operações sem risco, em que os clientes pagaram corretamente o valor devido.
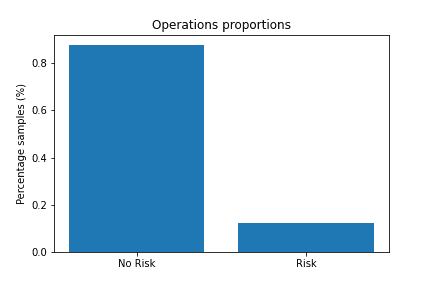
A relação entre os dois em nosso conjunto de dados com 252 mil amostras é de:
- 12.3% de operações de risco;
- 87.7% de operações comuns.
Logo, encontramos um problema! Nossos dados estão desbalanceados.
Sanity check no dataset
Vamos responder três perguntas:
- Há diferenças entre os dados de entrada da base de treinamento e os da base de testes? Não.
- Quais os tipos de dados nos dados de treinamento? São amostras para treinamento com respostas e sem respostas e variáveis de entrada, conforme descrito no site.
- Qual o percentual de valores nulos? 0%, não há nenhum valor nulo em nenhuma das colunas.
As três perguntas são avaliadas e respondidas em detalhes no notebook.
Limpeza básica de dados
Como verificamos na etapa anterior que não há desfalques, podemos focar em entender quais colunas que possuem dados de texto podem ser substituídas por números.
Para isso, vamos dar uma olhada no histograma das seguintes variáveis, que possivelmente têm poucas categorias:
- Married/Single;
- Car_Ownership;
- House ownership.
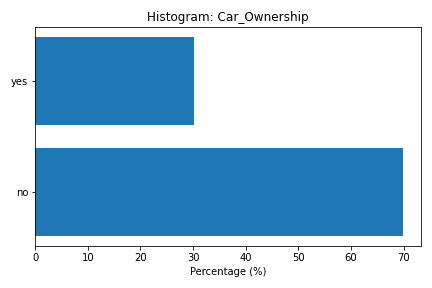
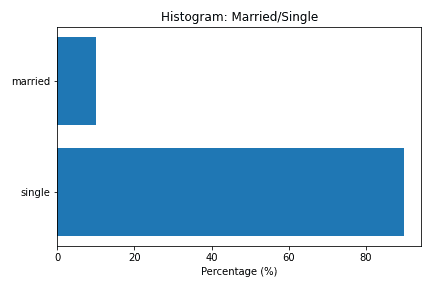
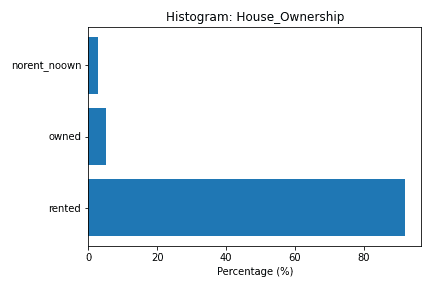
Ao analisar os gráficos acima verificamos que apenas a variável “House_Ownership” tem mais de uma categoria. Portanto, para limpar esses dados, vamos realizar duas operações descritas no código abaixo:
- Converter a coluna “Married/Single” em “Is_Single”, onde o valor 1 corresponde a “solteiro” e 0 a “casado”;
- Converter a coluna “Car_Ownership” em “Has_Car”, onde o valor 1 corresponde a “sim” e 0 a “não”.
- Remover as colunas “Car_Ownership” e “Married/Single”.
Com a nossa função de limpeza definida, podemos prosseguir para a exploração da base de dados.
2) Fazendo uma análise exploratória
Nesta etapa, vamos realizar dois procedimentos:
- Análise de correlações entre as variáveis modelo e a variável alvo (risco);
- Análise de dados baseada em hipóteses.
Correlações entre as variáveis
A princípio, buscamos entender se existe uma correlação numérica entre as variáveis de entrada do modelo e a variável que desejemos prever. Podemos visualizar nossos dados no gráfico abaixo, que mostra o mapa de calor da correlação entre as variáveis:
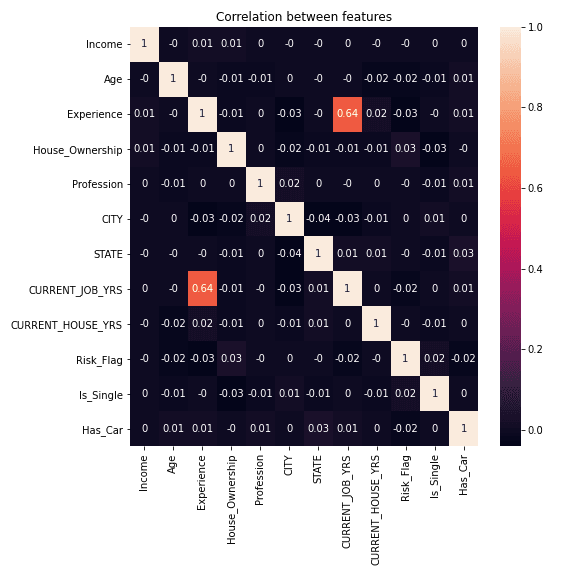
É possível concluir, então, que:
- Existem correlações positivas entre a variável “experiência profissional” e “anos no emprego atual”, o que faz sentido, visto que a senioridade de um profissional é desenvolvida através dos anos de experiência;
- Não existem outras correlações relevantes desta análise.
Nota: com as variáveis categóricas, foi feita uma transformação nos dados em que, para cada categoria, foi atribuído um número sequencial de 0 até o número de categorias.
Hipóteses
Logo, vamos dividir as variáveis de nosso conjunto de dados baseado no segmento de demografia, em que faremos nossas análises baseada em hipóteses.
Nota: o ideal a ser realizado nesta etapa é a exploração de dados por todos os diferentes segmentos de forma mutuamente exclusiva e coletivamente exaustiva, como, por exemplo, analisar os aspectos demográficos, profissionais e de patrimônio. Neste texto, deixamos outras análises de fora. Se você ficou interessado no problema, você pode fazer uma cópia do Jupyter notebook, criar suas hipóteses e compartilhar conosco nos comentários!
Demografia
Nessa etapa, estamos interessados em entender a relação entre as variáveis de renda (“Income”), idade (“Age”) e estado (“State”). Vamos propor duas hipóteses:
Pessoas jovens que têm baixa renda fazem parte de um perfil de risco?
Para responder essa pergunta, vamos analisar três gráficos que mostram a relação de renda média por idade para cada um dos grupos.
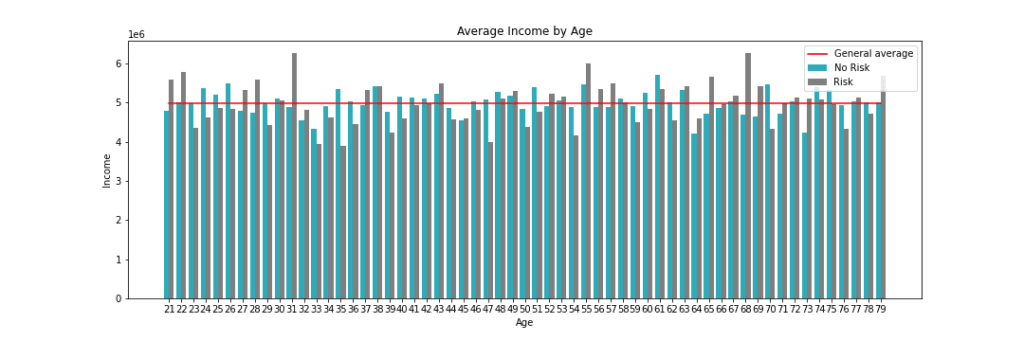
Nesse primeiro gráfico, que mostra todas as idades, de 21 a 79 anos, podemos ver que:
- Algumas idades de grupos de risco possuem uma renda maior que a média geral e renda maior que a das pessoas na mesma faixa etária;
- Não existe um crescimento linear entre idade e renda.
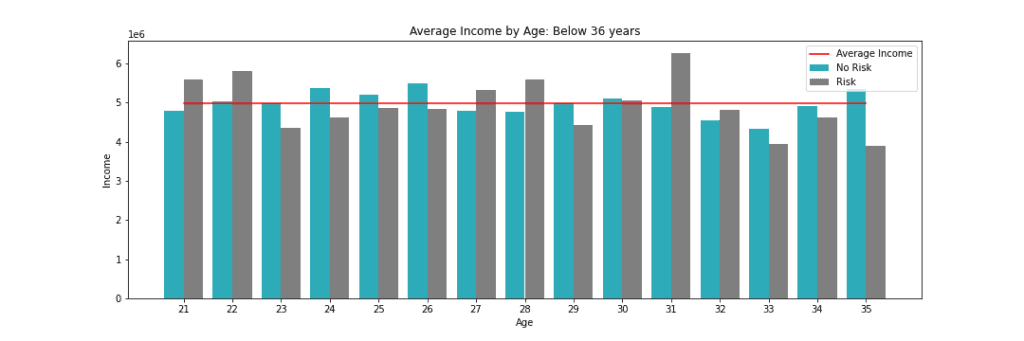
No segundo gráfico, com foco nos adultos abaixo de 36 anos podemos ver que:
- 42% dos jovens do grupo de risco recebem mais que os demais na mesma faixa, considerando as idades de 21, 22, 27, 28, 31 e 32 anos. É importante notar que, desses, 5 recebem acima da média geral;
- Os demais 58% recebem abaixo que seus pares na mesma idade;
- A relação de receita e risco não é linear com a idade, podendo ser melhor explicada por outros fatores como: cidade, profissão e patrimônio.
Em seguida, nossa análise propõe perguntar:
Existe algum estado com uma proporção muito maior de operações de risco do que outros?
Para responder essa pergunta, vamos analisar dois gráficos que demonstram o risco por estado.
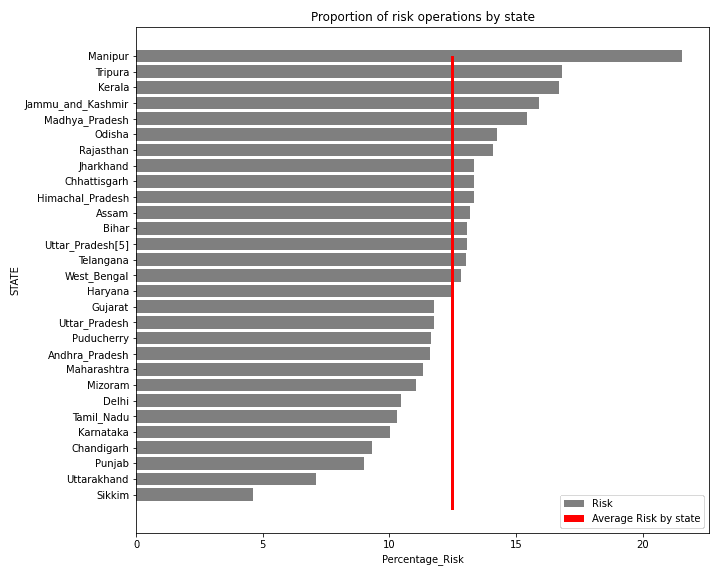
No primeiro gráfico, podemos ver a proporção de clientes de risco dentro de cada estado, em que:
- 5 cinco estados possuem uma taxa de 15% de inadimplência enquanto a média é de 12%;
- Podemos ver que os estados de Manipur e Sikkim se destacam por possuírem o maior e o menor percentual respectivamente. Talvez esta diferença possa indicar um padrão de clientes diferente em cada região ou um número reduzido de amostras.
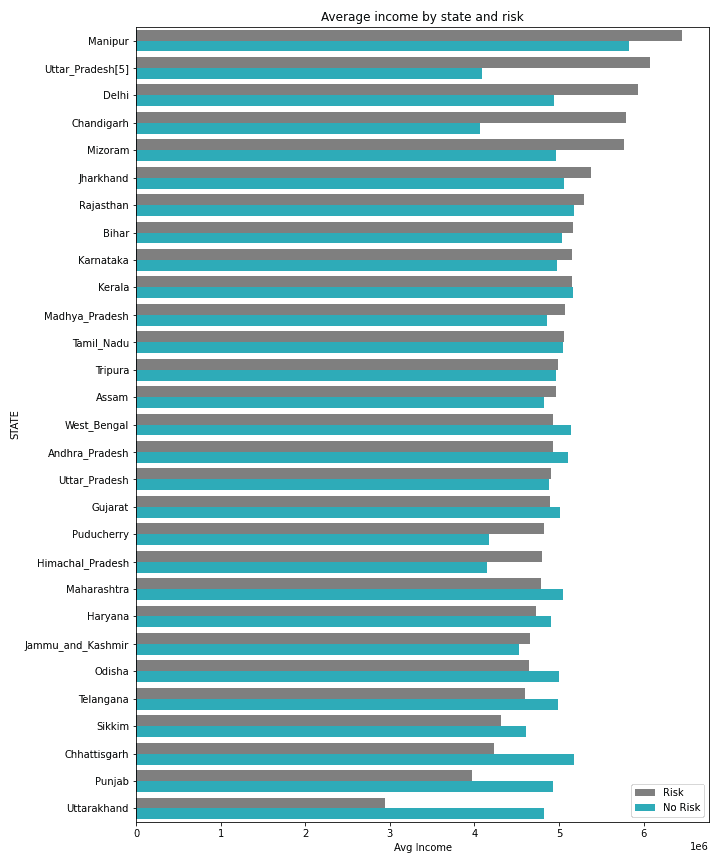
No segundo gráfico, podemos ver a relação de renda média do estado por operações de risco. Nele, é perceptível a diferença de inadimplência por estado baseado na renda. Podemos, então, dividir os estados em três grupos:
- Estados cujo perfil inadimplente são pessoas com maior renda: estado de Manipur até Jharkhand, incluindo Puducherry e Himachal_Pradesh;
- Estados cujo perfil inadimplente são pessoas com menor renda: como Uttarakhand, Punjab, Chattisgarth, entre outros;
- Estados cuja diferença de renda entre os grupos não é perceptível: como West_Bangal, Tripura, entre outros.
Recapitulando as hipóteses de demografia:
- Pessoas jovens que têm baixa renda fazem parte de um perfil de risco?
Não. Há, inclusive, jovens que possuem uma renda maior que a média geral dos clientes e não estão em perfil de risco. Talvez uma segmentação por estado ou aspectos profissionais consiga responder melhor esta pergunta.
- Existe algum estado com uma proporção muito maior de operações de risco do que outros?
Sim, existe uma diferença no risco de operação por estado. Além disso, é possível dividir os estados por clientes inadimplentes que possuem maior e menor renda que os clientes comuns.
3) Criando um modelo de machine learning para análise de risco
Nesta seção, vamos criar o modelo preditivo de nosso problema. Para isso, vamos passar pelas seguintes etapas:
- Definição da relação entre o modelo e suas predições;
- Definição das métricas de avaliação para o modelo;
- Desenvolvimento e avaliação do modelo preditivo.
Relação entre modelo de análise e predições de risco
Para o nosso caso, em que estamos lidando com um problema de classificação, temos:
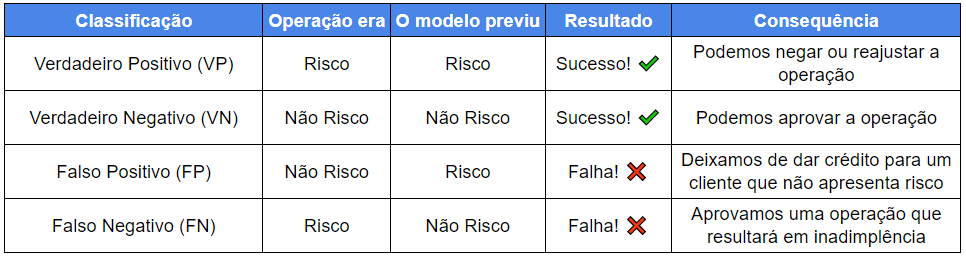
A partir do quadro acima podemos priorizar as métricas de acordo com as necessidades do negócio.
Por exemplo, em operações com alto valor de crédito, é preferível focar em não deixar que ocorra uma inadimplência ao custo de negar operações que não sejam arriscadas. Ou seja, o falso negativo é o pior cenário.
Em contrapartida, para uma empresa que tem foco em nano-crédito, pode ser mais prejudicial deixar de dar crédito e reduzir seu volume de transações, ao invés de detectar o risco. Nesse caso, um falso positivo é o pior cenário.
Métricas de avaliação para o modelo
Para esse problema, utilizaremos duas métricas para avaliar o desempenho dos modelos de machine learning criados:
- ROC AUC: área sob a curva ROC (quanto maior, melhor)
- PR AUC: área sob a curva de Precision-Recall (quanto maior, melhor)
Não vamos entrar em detalhes sobre o funcionamento e cálculo de cada uma dessas métricas, porém podemos destacar os seguintes pontos que motivam a nossa escolha:
- Ambas as métricas avaliam o resultado do modelo independentemente de um ponto de corte para a predição. Ou seja, eu não preciso informar de antemão que o limiar para classificar uma operação como arriscada seja caso a probabilidade seja maior que 0.5 ou 0.75 ou 0.87;
- É possível comparar diretamente o resultado de um modelo com o outro e escolher o melhor baseado no critério de prioridade do negócio.
Além das duas métricas, também vamos ver a matriz de confusão de cada modelo, em que teremos a relação entre Verdadeiro Positivo, Verdadeiro Negativo, Falso Positivo e Falso Negativo.
Desenvolvimento e avaliação do modelo preditivo
Para o desenvolvimento do modelo, os dados foram divididos em três conjuntos:
- Treinamento — 70% dos dados serão usados para treinar o modelo de machine learning a partir de exemplos anteriores de operações comuns e de inadimplência;
- Teste — 20% dos dados serão usados para avaliar o modelo treinado. Neste conjunto de dados, poderemos mudar as estratégias de modelagem, além de testar diferentes algoritmos para entender qual o melhor resultado possível;
- Validação — 10% dos dados serão usados para a avaliação final. Ou seja, durante nenhum momento do desenvolvimento do modelo teremos contato com estes dados, simulando um cenário “real”.
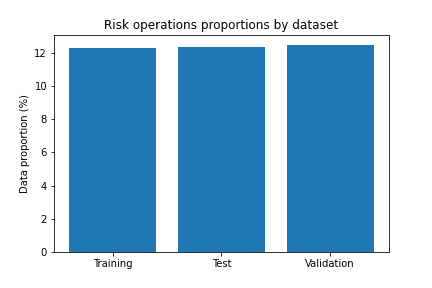
Para nos certificarmos de que não existe desproporção com relação ao número de operações inadimplentes em cada um dos conjuntos de dados, avaliamos o percentual de operações de risco em cada um deles.
Análise percentual
Na imagem abaixo, percebemos que não há diferença significativa, com todos em torno de 12%.
Logo, após alguns testes e diferentes modelagens abordadas, chegamos aos seguintes resultados com os dados de teste, comparando três diferentes algoritmos que podem ser vistos nos gráficos abaixo.
- Random Forest com ROC AUC de 0.94 e PR AUC de 0.59;
- Decision Tree (Árvore de decisão) com ROC AUC de 0.84 e PR AUC de 0.4;
- SVM com ROC AUC de 0.5 e PR AUC de 0.12.
O melhor resultado é proveniente do Random Forest e na imagem da direita é possível ver a relação entre as métricas de precision e recall para diferentes limiares de predição.
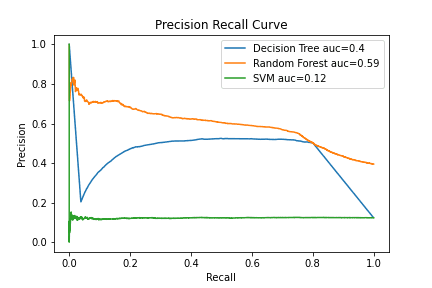
Agora, vamos avaliar o resultado do modelo escolhido (Random Forest) nos dados de validação e utilizando um limiar de predição de 0.85, ou seja:
- Caso o modelo preveja que uma operação é de risco com uma probabilidade de 85% , então ela é classificada como risco;
- Neste limiar, o valor de precision é de aproximadamente 0.58 e o valor de recall é de aproximadamente 0.6.
Essa imagem produzida por Andreas Holzinger exemplifica muito bem a diferença entre as duas métricas no momento de uma predição.

Abaixo, podemos ver uma matriz de confusão para o nosso problema, utilizando os dados de validação, ou seja, simulando um ambiente real:

Podemos ver, então, que:
- Classificamos corretamente 1.930 operações de inadimplência e erramos 1.209;
- Classificamos corretamente 20.730 operações de crédito e erramos 1.331.
Apenas estes resultados não conseguem tangibilizar os ganhos reais de nossa solução, portanto, façamos um pequeno exercício com valores possíveis.
4) Analisando os ganhos financeiros da solução de machine learning
Na última seção, criamos o nosso modelo de predição e encontramos a matriz de confusão para os dados de validação. Agora, podemos colocar os dados de predição em um contexto de negócio que poderia ser real.
Vamos imaginar, então, que a instituição financeira tenha contabilizado:
- Valor médio por operação de crédito: valor que em média um cliente pede de crédito;
- Lucro médio por operação: valor que a instituição recebe da operação de crédito acrescido de juros;
- Perda por inadimplência médio: valor que a instituição perde contabilizando o montante emprestado acrescido de outras despesas, como a tentativa de recuperação de crédito.
Neste exemplo, vamos trabalhar com os valores fictícios da tabela abaixo:

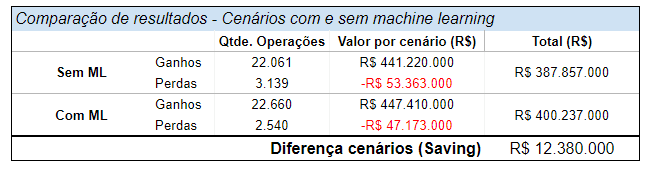
Agora, podemos colocar os nossos dados de validação em perspectiva e ver que:
- A instituição teve R$ 53.3M em perdas.
- O lucro total no período analisado foi de R$ 387.8M, com 25.2k operações de crédito.
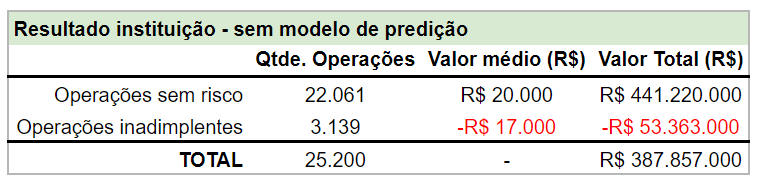
Agora, vamos experimentar utilizar o nosso modelo de predição de risco de crédito.
Para quantificar o resultado da nossa solução, vamos colocar em perspectiva os valores médios por operação em relação às predições realizadas e, em seguida, vamos calcular os ganhos e perdas totais.
Podemos dividir os resultados do modelo em:
Ganhos
- Situações em que não perdemos dinheiro ao dar crédito para as operações que seriam inadimplentes (Operação de risco e modelo previu risco);
- Situações em que aprovamos crédito corretamente e a instituição lucrará com a operação (Operação sem risco e modelo previu sem risco);
Perdas
- Situações em que aprovamos crédito incorretamente e a operação foi inadimplente (Operação era de risco e modelo previu como sem risco);
- Situações em que não aprovamos crédito para clientes que honrariam a dívida e consequentemente a instituição deixou de lucrar com o valor da operação com lucro (Operação era sem risco e modelo previu com risco).

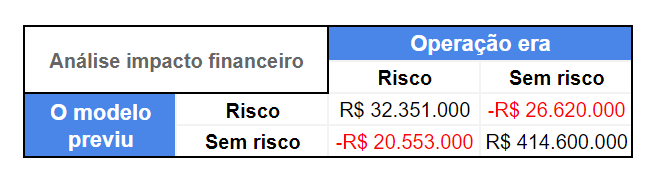
Ao transcrever os resultados da matriz acima para um formato de tabela podemos ver que, ao final, a instituição teria um resultado de R$ 400.2M, sendo:
- R$ 32.8M com economias via redução de perdas por inadimplência;
- Receita de R$ 416.6M proveniente de lucros com a operação;
- Perdas de R$ 47.1M devido a erros do modelo.
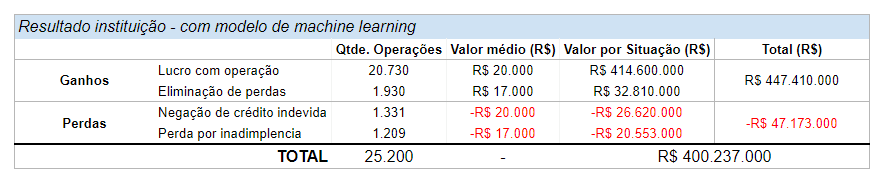
Ao compararmos os dois cenários (com e sem modelo) vemos que a implementação de um modelo de machine learning para avaliar o risco de operações de crédito traz uma economia de R$ 12.3 milhões:
E aí, vai ficar de fora?
Entendeu como funciona? Nós conseguimos confirmar, com essa simulação, que análises de riscos com machine learning podem trazer ganhos significativos para diversos tipos de negócio. Isso abre muitas portas!
A ciência de dados pode ser aplicada a todos os setores da sua empresa, de maneira a automatizar os processos de análise. Assim, a sua organização pode se tornar cada vez mais orientada por dados, ou data driven.
Se você já tem um procedimento de captação e tratamento de dados bem estruturado, pode ser a hora de turbinar sua rotina com tecnologia! Aproveite todo o potencial dos seus dados. Agende uma demonstração conosco.






